KI und Large Language Models (LLMs) Grundlagen
Table of Contents
Was ist Künstliche Intelligenz?
Schwache KI
Schwache KI im Vergleich zur Starken KI
Vielfältige Anwendungsfelder der schwachen KI
Die Anwendungsbereiche der schwachen KI sind vielfältig und zugleich beeindruckend: In der Medizin unterstützt sie Ärzte bei der Diagnosestellung durch detaillierte Bildauswertungen, im Verkehrswesen ermöglicht sie autonomes Fahren, in der Industrie automatisiert sie Fertigungsprozesse und im Kundenservice optimiert sie die Interaktion durch Chatbots. Ein weiteres markantes Beispiel für schwache KI sind Empfehlungssysteme, wie sie von Streaming-Diensten und Online-Shops genutzt werden. Diese analysieren das Verhalten und die Präferenzen der Nutzer und können so individuelle Empfehlungen aussprechen, die die Zufriedenheit der Kunden steigern und die Umsätze der Anbieter erhöhen.
Effizienz und Datenverarbeitungsvorteile der Schwachen KI
Ein wesentlicher Vorteil der schwachen KI liegt in ihrer Effizienz. Da sie für spezielle Aufgaben entwickelt wird, kann sie diese oft mit übermenschlicher Geschwindigkeit und Genauigkeit ausführen. Darüber hinaus ist die schwache KI in der Lage, große Datenmengen zu verarbeiten, die für einen Menschen überwältigend wären. Dies führt zu einer verbesserten Entscheidungsfindung, da die KI Systeme auf der Grundlage von Datenmustern, die sie identifizieren, Schlussfolgerungen ziehen können.
Ethische Herausforderungen und gesellschaftliche Verantwortung
Die Entwicklung der schwachen KI wirft jedoch auch wichtige ethische Fragen auf. Die Datenschutzproblematik ist dabei ebenso relevant wie die Sorge um den Verlust von Arbeitsplätzen durch Automatisierung. Während KI-Systeme Routinetätigkeiten übernehmen, müssen sich Arbeitskräfte zunehmend auf Tätigkeiten konzentrieren, die kreatives Denken und menschliche Interaktion erfordern. Des weiteren stellen sich Fragen zur Sicherheit: Wie können wir sicherstellen, dass KI-Systeme nicht manipuliert werden und fehlerhafte Entscheidungen treffen? Für eine verantwortungsvolle Integration dieser Technologien in die Gesellschaft ist es jedoch unerlässlich, dass entsprechende regulative Rahmenbedingungen geschaffen und ethische Richtlinien entwickelt
Starke KI
Das Konzept der starken Künstlichen Intelligenz
Starke KI, auch bekannt als General Artificial Intelligence (AGI), ist ein Konzept, das in der Forschungswelt immer noch eher Vision als Realität ist. Starke KI zielt darauf ab, ein umfassendes kognitives Verständnis zu entwickeln, das dem des Menschen gleichkommt. Dies bedeutet, dass eine starke KI in der Lage sein sollte, unabhängig von der Domäne oder dem Kontext zu lernen, zu verstehen und zu agieren. Sie würde über Intelligenz verfügen, die es ihr erlaubt, eigenständige Konzepte und Ideen zu entwickeln, abstrakte Gedanken zu führen und kreative Problemlösungen zu finden – und das über verschiedenste Bereiche hinweg.
Historischer Rückblick und aktueller Forschungsstand
Anforderungen an eine starke KI
Unterscheidung zwischen Schwacher und starker KI im maschinellen Sehen
Um dies zu verdeutlichen, betrachten wir ein Beispiel aus dem Bereich des maschinellen Sehens. Ein schwaches KI-System kann trainiert werden, um Katzen auf Bildern zu erkennen, indem es auf eine umfangreiche Datenbank mit Katzenbildern zurückgreift und Muster wie Formen und Texturen identifiziert, die für Katzen typisch sind. Eine starke KI jedoch würde nicht nur eine Katze erkennen, sondern auch verstehen, was eine Katze ist, wie sie sich verhält, welche ökologische Nische sie besetzt und wie sie mit anderen Wesen und Gegenständen in ihrer Umgebung interagiert.
Sprachverständnis bei starker KI
Starke KI in der Robotik
Das Konzept des Transferlernens bei starker KI
Das tiefe Verständnis, das von einer starken KI erwartet wird, bedeutet auch, dass sie in der Lage sein muss, Wissen von einer Situation auf eine andere zu übertragen. Beim Menschen nennen wir dies Transferlernen. Ein Kind, das lernt, dass es sich verbrennt, wenn es eine heiße Herdplatte berührt, wird diese Information nutzen, um vorsichtig zu sein, wenn es zum ersten Mal eine Kerzenflamme sieht. Eine starke KI müsste in der Lage sein, ähnliche abstrakte Verbindungen zwischen scheinbar unverbundenen Domänen herzustellen.
Weltmodellierung und Intuition in der starken KI
Ethik und Sicherheit in der starken KI
Ethik und Sicherheit sind bei der starken KI noch dringendere Anliegen als bei der schwachen KI. Wenn Maschinen menschenähnliche Fähigkeiten erlangen, stellt sich die Frage, wie sie moralische Entscheidungen treffen und wer für diese Entscheidungen verantwortlich ist. Die Idee einer KI, die eigene Ziele setzen und verfolgen kann, wirft fundamentale Fragen über die Kontrolle solcher Systeme und die potenziellen Risiken auf, die sie für die Menschheit darstellen könnten.
Die faszinierende Zukunft der starken KI
Trotz aller Herausforderungen und Bedenken bleibt die Entwicklung einer starken KI ein faszinierendes Ziel. Es hat das Potenzial, nicht nur die Art und Weise zu revolutionieren, wie wir mit Maschinen interagieren, sondern auch grundlegende Fragen darüber zu beantworten, was es bedeutet, intelligent zu sein. Wissenschaftler und Ingenieure arbeiten weltweit an den Grenzen dieser Technologie, und obwohl eine echte starke KI möglicherweise noch Jahrzehnte entfernt ist, wird jeder Schritt in diese Richtung unsere Fähigkeiten erweitern und uns möglicherweise neue Perspektiven auf unser eigenes Bewusstsein und unsere Intelligenz eröffnen.

Technologien und Algorithmen der Künstlichen Intelligenz
Grundlagen und Geschichtliches der KI-Technologie
Im Kern der künstlichen Intelligenz (KI) stehen Algorithmen – strukturierte Anweisungssets, die Computern beibringen, wie sie Aufgaben ausführen, Entscheidungen treffen und Probleme lösen können, die traditionell menschliche Intelligenz erfordern würden. Diese Algorithmen sind das Rückgrat, das es Maschinen ermöglicht, aus Erfahrung zu lernen, sich anzupassen und Aktionen durchzuführen, die, wären sie von Menschen ausgeführt, als „intelligent“ betrachtet würden. Die Algorithmen, die die heutige KI antreiben, sind das Ergebnis einer langen Entwicklungsgeschichte, die so alt ist wie die Informatik selbst. Schon in den 1950er Jahren begannen Wissenschaftler damit, mathematische Modelle zu erforschen, die grundlegende kognitive Prozesse nachbilden sollten. Alan Turing, oft als Vater der theoretischen Informatik und der Künstlichen Intelligenz angesehen, stellte die Frage „Können Maschinen denken?“ und entwickelte den Turing-Test als ein Kriterium der Intelligenz in einer Maschine.
Das breite Spektrum der KI-Methoden und -Modelle
In der dynamischen Welt der Künstlichen Intelligenz (KI) bildet ein vielschichtiges Ökosystem an Methoden und Modellen das Rückgrat der technologischen Fortschritte, die unsere Gesellschaft prägen. Vom maschinellen Lernen, das sich in überwachte, unüberwachte und verstärkende Lernparadigmen aufgliedert, bis hin zu den tiefgreifenden Strukturen des Deep Learnings, entfaltet sich ein komplexes Netzwerk aus Algorithmen und Ansätzen. Diese Strukturen ermöglichen es Maschinen, aus Erfahrungen zu lernen, sich anzupassen und komplexe Aufgaben zu erfüllen. Die Bereiche wie Natural Language Processing und Computer Vision veranschaulichen die Fähigkeit von KI-Systemen, menschliche Sprache und visuelle Informationen zu interpretieren und zu verarbeiten. In der Robotik, Expertensystemen, Schwarmintelligenz und weiteren spezialisierten Feldern finden sich innovative Ansätze, die von pfadfindenden Algorithmen bis hin zu evolutionären Berechnungen reichen. Jede dieser Disziplinen spiegelt einen einzigartigen Aspekt der KI wider und gemeinsam bilden sie ein Mosaik der Möglichkeiten, das das Potenzial hat, jede Ecke unserer technologischen Existenz zu verändern.
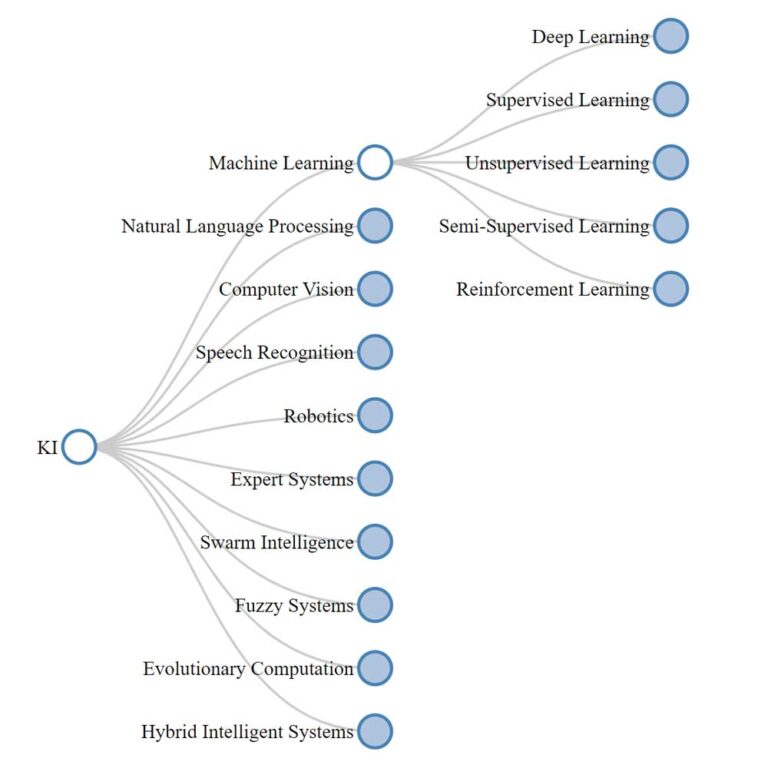
Maschinelles Lernen als Kerntechnologie der KI
Die Evolution der Datenverarbeitung
Machine Learning, ein zentraler Zweig der künstlichen Intelligenz, hat sich zu einem der einflussreichsten und dynamischsten Bereiche der modernen Technologie entwickelt. Im Vergleich zu stärker regelbasierten Ansätzen wie Expertensystemen, die auf einem festgelegten Satz von Wenn-Dann-Beziehungen beruhen, ist ML flexibler und kann unvorhergesehene Datenpunkte verarbeiten. Während sich Robotics auf die physische Interaktion mit der Umgebung konzentriert und Computer Vision primär darauf ausgerichtet ist, visuelle Informationen zu interpretieren, hebt sich ML durch seinen Schwerpunkt auf Lernprozesse und Mustererkennung in komplexen Datensätzen ab. Seine Grundlagen beruhen auf der Prämisse, dass Maschinen, ähnlich wie Menschen, aus Erfahrungen lernen und ihre Leistung im Laufe der Zeit verbessern können. Diese Fähigkeit wird erreicht, indem Computerprogramme erstellt werden, die auf Daten zugreifen und diese verwenden, um selbstständig zu lernen und Entscheidungen zu treffen. Mit dem Aufkommen des Internets und der exponentiellen Zunahme der verfügbaren Daten hat sich Machine Learning von einer akademischen Neugier zu einer praktischen Notwendigkeit entwickelt, die viele Aspekte unseres täglichen Lebens durchdringt.
Erkennungsmuster und Anwendungsbereiche von Machine Learning
Machine Learning-Algorithmen sind in der Lage, Muster und Strukturen in Daten zu erkennen, die für Menschen zu komplex oder nicht wahrnehmbar sind. Dies ermöglicht es Maschinen, Vorhersagen zu treffen oder Entscheidungen basierend auf großen Mengen von Daten ohne explizite Programmierung zu treffen. Diese Algorithmen haben sich in einer Vielzahl von Anwendungen als nützlich erwiesen, von der Erkennung von Betrug im Finanzsektor über die Personalisierung von Inhalten in den sozialen Medien bis hin zur Verbesserung von Diagnoseverfahren im Gesundheitswesen. Die Wissenschaft hinter Machine Learning ist reichhaltig und vielfältig, mit einer Mischung aus Informatik, Statistik, Mathematik und Domain-Wissen, die gemeinsam ein starkes Werkzeug für die Datenanalyse bilden.
Das Fundament des Machine Learnings: Daten und Training
Der Prozess des Machine Learnings beginnt typischerweise mit der Sammlung und Aufbereitung von Daten, die als Trainingsset dienen. Diese Daten können strukturiert oder unstrukturiert sein und aus einer Vielzahl von Quellen stammen, darunter Sensoren, digitale Interaktionen und menschliche Eingaben. Sobald die Daten gesammelt sind, wird der Lernprozess gestartet. Im Falle des überwachten Lernens, einer häufigen Methode des Machine Learnings, werden Algorithmen mit Beispieldaten trainiert, die sowohl Eingangsvariablen als auch entsprechende Ausgangsvariablen, bekannt als Labels, enthalten. Durch dieses Training lernt der Algorithmus, Eingaben zu Ausgaben zu korrelieren und kann beginnen, Vorhersagen für neue, ungelabelte Daten zu treffen.
Das Fundament des Machine Learnings: Daten und Training
Der Prozess des Machine Learnings beginnt typischerweise mit der Sammlung und Aufbereitung von Daten, die als Trainingsset dienen. Diese Daten können strukturiert oder unstrukturiert sein und aus einer Vielzahl von Quellen stammen, darunter Sensoren, digitale Interaktionen und menschliche Eingaben. Sobald die Daten gesammelt sind, wird der Lernprozess gestartet. Im Falle des überwachten Lernens, einer häufigen Methode des Machine Learnings, werden Algorithmen mit Beispieldaten trainiert, die sowohl Eingangsvariablen als auch entsprechende Ausgangsvariablen, bekannt als Labels, enthalten. Durch dieses Training lernt der Algorithmus, Eingaben zu Ausgaben zu korrelieren und kann beginnen, Vorhersagen für neue, ungelabelte Daten zu treffen.
Adaptivität und Fortschritte im Deep Learning
Die Leistungsfähigkeit dieser Algorithmen ist nicht statisch; sie entwickelt sich weiter, da sie auf neuen Daten und im Kontext neuer Problemstellungen eingesetzt werden. Dieser adaptive Aspekt des Machine Learnings ist von entscheidender Bedeutung, da er es ermöglicht, dass die Algorithmen im Laufe der Zeit verbessert werden und genauer werden. Darüber hinaus hat der Bereich des Deep Learning, ein Subset des Machine Learnings, der sich auf künstliche neuronale Netze konzentriert, die Fähigkeit von Algorithmen zur Datenverarbeitung weiter verbessert. Diese tiefen neuronalen Netze sind inspiriert von der menschlichen Gehirnstruktur und können extrem komplexe Muster in großen Datenmengen erkennen.
Herausforderungen und Qualitätssicherung im Machine Learning
Während Machine Learning enorme Möglichkeiten bietet, ist es nicht ohne Herausforderungen. Ein Hauptanliegen ist die Qualität und Quantität der verfügbaren Trainingsdaten, da Algorithmen nur so gut sind wie die Daten, mit denen sie gefüttert werden. Wenn die Daten verzerrt oder unvollständig sind, können die daraus resultierenden Modelle irreführende Ergebnisse liefern. Darüber hinaus stellt die Interpretierbarkeit von Machine Learning-Modellen, insbesondere von tiefen neuronalen Netzen, eine Herausforderung dar, da diese Modelle oft als „Black Boxes“ betrachtet werden, deren interne Arbeitsweisen schwer zu verstehen sind. Dies hat zu Forderungen nach mehr Transparenz und Erklärbarkeit in Machine Learning geführt.
Ethik und Verantwortung in der Ära des Machine Learnings
Schließlich ist die Ethik des Machine Learnings ein wachsendes Feld der Untersuchung, da die Entscheidungen, die von Algorithmen getroffen werden, zunehmend Auswirkungen auf das reale Leben haben. Fragen der Verzerrung, der Verantwortlichkeit und des Datenschutzes stehen im Mittelpunkt der Diskussion um Machine Learning. Trotz dieser Herausforderungen bleibt Machine Learning ein faszinierendes und sich schnell entwickelndes Feld, das das Potenzial hat, nahezu jeden Aspekt unserer Gesellschaft zu transformieren. Wissenschaftler und Praktiker arbeiten ständig an der Verbesserung von Machine Learning-Technologien, um ihre Genauigkeit, Effizienz und Anwendbarkeit zu erhöhen, was die Tür zu einer noch stärker integrierten und intelligenten technologischen Umgebung öffnet.
Natural Language Processing (NLP) & Large Language Models (LLMs)
NLP und LLMs - Wegbereiter für Maschinenkommunikation
Natural Language Processing (NLP) liegt an der Schnittstelle von Informatik, künstlicher Intelligenz und Linguistik und strebt danach, Maschinen zu ermöglichen, menschliche Sprache so zu verstehen und zu interpretieren, dass sinnvolle Dialoge möglich werden. Die Forschung und Entwicklung in diesem Bereich haben enorme Fortschritte gemacht, insbesondere mit dem Aufkommen von Large Language Models (LLMs) wie GPT (Generative Pre-trained Transformer), die auf umfangreichen Textmengen trainiert wurden, um eine Vielzahl von NLP-Aufgaben zu bewältigen. Diese Modelle haben die Fähigkeit, menschenähnliche Texte zu generieren, zu übersetzen, Fragen zu beantworten, und in einigen Fällen sogar anspruchsvolle Aufgaben wie das Schreiben von Code zu erledigen.
Entwicklungspfad von NLP: Von Regeln zu KI-Modellen
Die Evolution von NLP ist untrennbar mit der Entwicklung leistungsfähiger Algorithmen und der Verfügbarkeit großer Datenmengen verbunden. Ursprünglich begann NLP mit regelbasierten Systemen, die strukturierte Regeln zur Verarbeitung von Text verwendeten. Diese wurden jedoch schnell von statistischen Modellen überholt, die auf Wahrscheinlichkeitsverteilungen und reichhaltigen textuellen Korpora basierten. Der nächste große Durchbruch kam mit maschinellem Lernen und insbesondere mit der Anwendung von Deep Learning-Techniken, die es Maschinen ermöglichten, komplexe Muster in Daten zu erkennen. LLMs wie GPT-3 und GPT-4 haben die Grenzen dessen, was maschinelles Lernen leisten kann, erweitert, indem sie es Computern ermöglichen, Sprache in einer Weise zu nutzen, die der menschlichen Fähigkeit, Kontext zu verstehen und zu generieren, nahekommt.
Transferlernen: Die Vielseitigkeit von Large Language Models
Eines der bemerkenswertesten Merkmale von LLMs ist ihre Transferfähigkeit; ein einziger Algorithmus kann eine Vielzahl von Aufgaben ohne spezifische Aufgabenanpassung ausführen. Dies ist ein Paradigmenwechsel im Vergleich zu früheren Ansätzen, bei denen für jede neue Aufgabe ein neues Modell trainiert werden musste. LLMs nutzen eine gewaltige Anzahl von Parametern – GPT-4 zum Beispiel verwendet schätzungsweise 1,8 Billionen – die es dem Modell ermöglichen, subtile Nuancen der menschlichen Sprache zu erfassen. Durch Pre-Training auf einer breiten Palette von Textquellen und anschließender Feinabstimmung auf spezifische Aufgaben haben diese Modelle beeindruckende Ergebnisse in Bereichen wie Textverständnis, Zusammenfassung und Erstellung erreicht.
Praktische Anwendungsszenarien für NLP und LLMs
Die Anwendungen von NLP und LLMs sind weitreichend und wachsen stetig. Im Bereich der Unternehmensautomatisierung werden sie für Aufgaben wie Kundendienst und Dokumentenanalyse eingesetzt. Im Bildungswesen unterstützen sie personalisiertes Lernen und Bewertungen. In der Gesundheitsbranche helfen sie bei der Verarbeitung von Patienteninformationen und der Unterstützung von Diagnoseverfahren. Darüber hinaus werden LLMs zunehmend in kreativen Feldern eingesetzt, um Autoren bei der Inhaltsentwicklung zu unterstützen oder sogar eigenständig künstlerische Texte zu erstellen.
Herausforderungen und Zukunftsperspektiven im NLP
Während LLMs außergewöhnliche Fähigkeiten in der Sprachverarbeitung demonstrieren, bleiben Herausforderungen bestehen, wie die Sicherstellung von Genauigkeit, Vermeidung von Verzerrungen und die Interpretation von Ambiguität – alle inhärenten Aspekte der menschlichen Sprache. Die Forschung in diesem Bereich ist dynamisch und interdisziplinär, wobei Wissenschaftler aus verschiedenen Fachrichtungen zusammenarbeiten, um diese Herausforderungen zu überwinden. Fortschritte im NLP werden weiterhin von Verbesserungen in den Algorithmen, der Rechenleistung und den Methoden zum Sammeln und Verarbeiten von Sprachdaten angetrieben werden. Die Zukunft von NLP und LLMs ist unglaublich vielversprechend, da sie das Potenzial haben, die Art und Weise, wie wir mit Maschinen interagieren, grundlegend zu verändern, was die Tür zu einer noch stärker integrierten und intelligenten technologischen Umgebung öffnet.
Schlusswort
Zusammenfassend ist die Beschäftigung mit Künstlicher Intelligenz mehr als ein intellektuelles Abenteuer; sie ist eine Notwendigkeit in einer Welt, in der Technologien wie GPT-4 immer stärker in unseren Alltag integriert werden. Die Multimodalität und fortwährende Entwicklung von LLMs zeigen, dass wir bald vor der Frage stehen, wie und wann diese Systeme verantwortungsvoll in verschiedenen Bereichen eingesetzt werden können.
Die mögliche Entstehung einer Superintelligenz, die durch neue Erfindungen in der Hardware-Technologie angetrieben wird, wirft zudem fundamentale Fragen auf, die weit über technische Aspekte hinausgehen. Es ist unerlässlich, dass wir diesen Entwicklungen mit einer Mischung aus Neugier und kritischer Reflexion begegnen, um einen verantwortungsbewussten Umgang mit diesen fortschrittlichen Technologien zu gewährleisten.
Unser Ziel war es, Ihnen ein klares Verständnis der Grundpfeiler der KI zu vermitteln und Sie für die tiefergehenden Diskussionen rund um dieses Thema zu rüsten. Wir hoffen, dass dieser Artikel nicht nur als Wissensgrundlage dient, sondern auch als Ansporn, um die vielschichtigen Dimensionen der KI – sei es in der Forschung, Industrie oder im alltäglichen Gebrauch – zu erforschen und mitzugestalten.







